Introducing Health Monitoring
Ghostwriter monitors the health of its services in two ways: Docker health checks and internal monitoring and testing.Docker Health Checks
Docker automatically monitors the containers viaHEALTHCHECK commands (see Docker documentation for technical information). These commands check to make sure the service is responding and basic functionality is working.
The results of these commands can be checked with this command:
0), the Status column will show healthy. Any other exit code will flip the status to unhealthy, indicating the service is likely not functioning properly.
By default, the commands run with these attributes that can be adjusted via Ghostwriter CLI’s config set command:
-
Start running after 30s (
HEALTHCHECK_START, default is30s) -
Run every 120s (
HEALTHCHECK_INTERVAL, default is120s) -
Timeout after 10s (
HEALTHCHECK_TIMEOUT, default is10s) -
Will be retried once (
HEALTHCHECK_RETRIES, default is1)
Internal Testing and Monitoring
Ghostwriter also tests each service more thoroughly with two API endpoints:- /status/
- /status/simple/
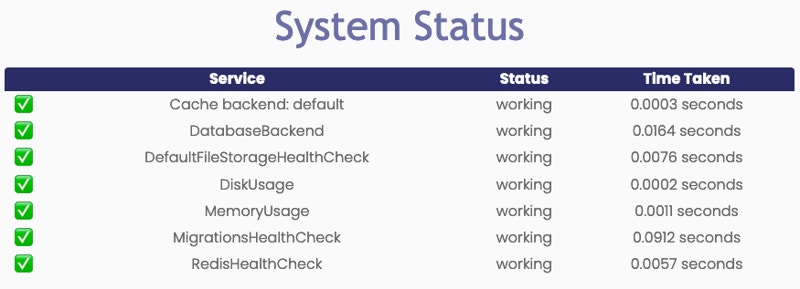
This endpoint can also return a JSON version of the test results if you set the
Accept: application/json header.| Response | Response Code | Description |
|---|---|---|
| OK | 200 | System is healthy |
| WARNING | 200 | One or more tests did not pass and you should check the detailed status endpoint |
| ERROR | 500 | There was an unexpected error indicating a critical issue |
Configuration
The dashboard services map to the following configuration variables:-
DiskUsage:
HEALTHCHECK_DISK_USAGE_MAX(Default is90[percentage]) -
MemoryUsage:
HEALTHCHECK_MEM_MIN(Default is100[in MB])
.env file or with Ghostwriter CLI (this sets and reads from .env). For changes in .env or using the CLI, bring containers down and up.
Example .env snippet with default values:
Automated Monitoring
You can automate monitoring with something like Uptime Kuma or a similar tool. The recommended logic is:- Request the /status/simple/ endpoint
- Check for the response code and content
-
If
OKis not in the response or the response code is not200, send an alert with a link to /status/ for details
working status. A service experiencing a problem will have a descriptive warning or error message that will tell you why it failed the test. You can use this information to customize your monitoring alert.